That is an excellent explanation full of great intuition building!
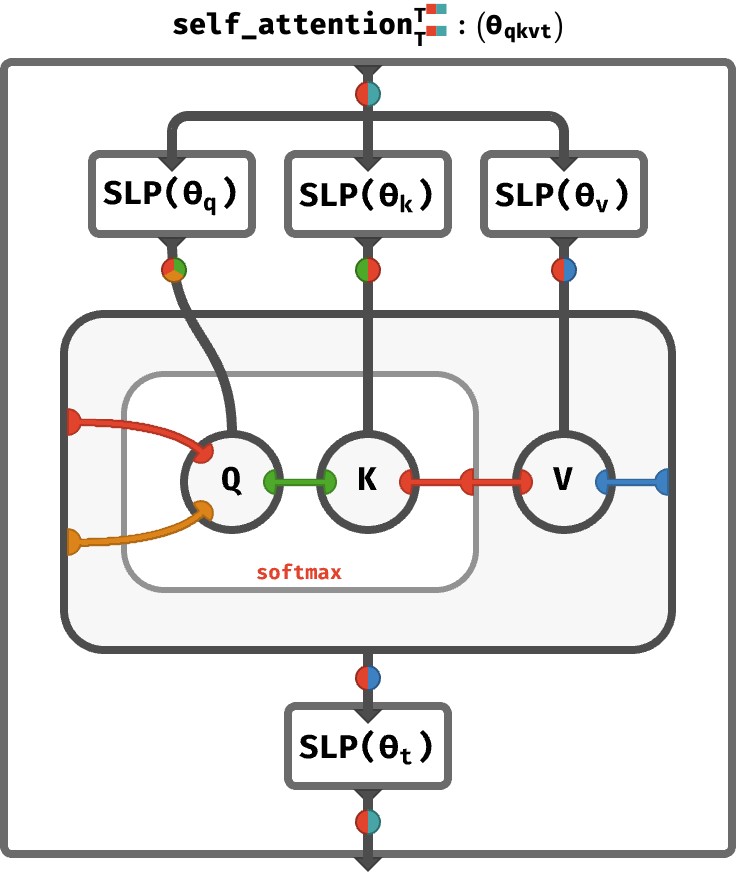
If anyone is interested in a kind of tensor network-y diagrammatic notation for array programs (of which transformers and other deep neural nets are examples), I wrote a post recently that introduces a kind of "colorful" tensor network notation (where the colors correspond to axis names) and then uses it to describe self-attention and transformers. The actual circuitry to compute one round of self-attention is remarkably compact in this notation:
https://math.tali.link/raster/052n01bav6yvz_1smxhkus2qrik_07...
Here's the full section on transformers: https://math.tali.link/rainbow-array-algebra/#transformers -- for more context on this kind of notation and how it conceptualizes "arrays as functions" and "array programs as higher-order functional programming" you can check out https://math.tali.link/classical-array-algebra or skip to the named axis followup at https://math.tali.link/rainbow-array-algebra
Jay Alammar is one of the greats in our field and we are lucky to have him.
{kind=link}
More excellent resources from Jay and others:
The Illustrated Transformer - http://jalammar.github.io/illustrated-transformer/
Beyond the Illustrated Transformer - https://news.ycombinator.com/item?id=35712334
LLM Visualization - https://bbycroft.net/llm